SQLFluff Tutorial: Automate SQL Linting for Team Development
Introduction
Code style guides aren’t new. Your style guide acts as a basic code blueprint for your team during all parts of the software development lifecycle. Most popular languages have many options for a linting tool which can help enforce these style guides by conducting static code analysis on your repos. Style guides and linters help standardize code across the team which can drastically improve code-readability and make new developer onboarding a little bit easier.
SQL code has always been treated a little differently. Each developer has their own opinion on whether SQL keywords should be in caps or lowercase. Some developers space code out across many lines, while others put triple nested sub-queries on a single line.
Standardization becomes necessary as your team grows and the number of .sql files in your repos increase. Here’s how I recommend implementing this standardization using SQLFluff as an automatic SQL code linter…
Step 1: Clone the repo
I’ve created a repo with everything you need to get started with SQL Fluff. Check it out here.
You can learn more about the SQLFluff package here. There are tons of SQL dialects supported. One of my favorite references in their docs is this guide for implementing across a team. These steps are essential for adoption of the tool to be successful.
Here are the files you will find in this repository:
FluffySQLLinter repo
├── .github/workflows <- CI/CD pipeline configuration
├── sql_files/ <- Directory to place .sql files to lint in
├── good_sql.sql
├── bad_sql.sql
├── .sqlfluff <- SQL Fluff configuration file
├── Makefile <- CLI commands to setup and lint files
├── README.md <- Repo documentation
├── requirements.txt <- Python project dependencies
Clone the repository onto your machine and follow the instructions in the README to get started locally.
Step 2: Setup the linting pipeline
The steps above will help you get started using SQLFluff locally on your machine, but for the tool to be easily accessible for everyone on the team you should use a workflow runner like GitHub Actions or Azure DevOps pipelines.
To setup this workflow in GitHub Actions, you just need the makefile.yml file in the .github/workflows directory. The current configuration of this file will trigger a workflow run every time there is a new PR created (into any branch) or a commit is pushed to the main branch.
In Azure DevOps, you can navigate to the pipelines tab and point towards this YAML file to setup the pipeline. Azure DevOps also allows you to trigger ad hoc runs of the pipeline targeted towards any specific branch.
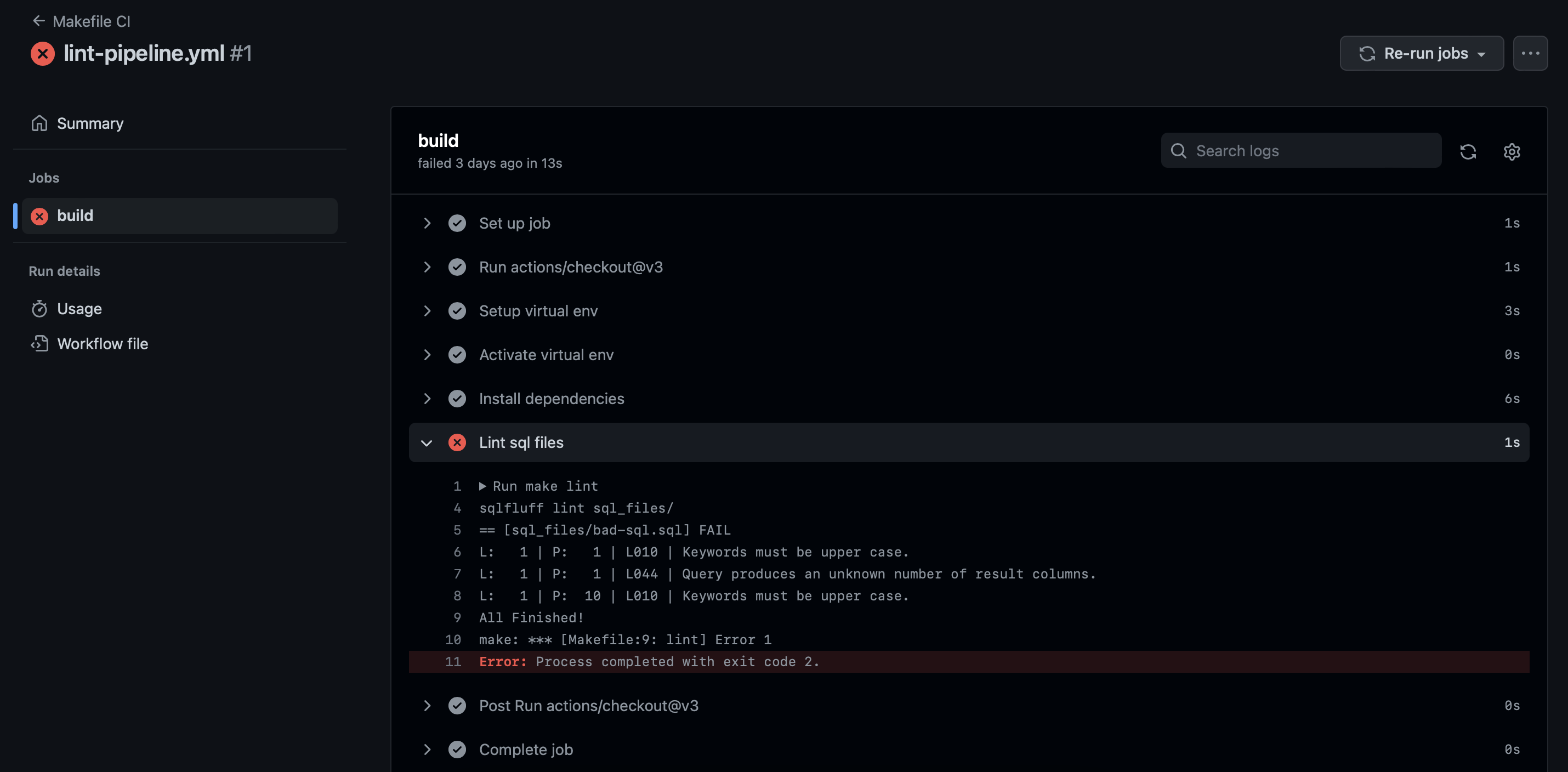
Step 3: Play with the config
Now it’s time to begin to customize the rules that will be applied during your sql code scans. I’d recommend making this a team exercise, where you place various examples of the groups’ SQL code files into the sql_files/ directory and see how the customization I’ve set reacts to your code patterns.
You can see all available rules here in the documentation.
Step 4: Enforce rules on PR
Once the team has had time to get comfortable with SQLFluff and the desired configuration is in place, it’s time to start enforcing these rules as new code is written.
sqlfluff fix CLI command. Read more here.In both GitHub and Azure DevOps this can be accomplished by setting a status check policy on the main branch. This will require that all code introduced to this branch successfully passes the linting check before it can be merged.
Check out the docs for each below:
- Azure DevOps: Setting up branch policy settings
- GitHub: Setting up status check policy
Next steps
This framework will help begin to standardize your SQL code format throughout your repositories. Other popular data science languages like Python have similar linting tools (such as flake8 and pylint) that can be implemented using these same steps. All are customizable to allow you to focus on what matters to your team.